Introduction
Cet article présente comment prendre en main Apache Kafka (+ ZooKeeper) en Scala. La version de Kafka utilisée est 0.8.2, la version de ZooKeeper est 3.4.6 (du moins je pense, car il s’agit de la version empaquetée dans Kafka 0.8.2), la version de Scala est 2.11.7. Enfin, j’utilise l’environnement de développement Intellij Idea dans sa version 14.1.4.
L’objectif principal de cet article est d’expliquer toutes les étapes de la mise en place d’un projet Kafka. L’application réalisée est très simple et fonctionne en local.
Qu’est ce que Kafka?
Définition globale
Kafka est un « système orienté message de type publication / souscription distribué ». Autrement dit, Kafka est un système permettant de gérer le flux de messages entre des producteurs (de messages) et des consommateurs (de messages aussi). Un message correspond à un couple clé/valeur de données. Un message peut être un log d’une machine, un vecteur de données, une liste de valeurs de capteurs à un instant t, etc.
Cet outil est de plus en plus populaire car il est bien intégré par les distributeurs de Hadoop (Hortonworks, Cloudera et compagnie). Il est également intégré à l’utilisation de Spark grâce à son connecteur spécifique. Ainsi, Kafka est le système orienté message pour le Big Data.
Un petit mot sur ZooKeeper qui est un système centralisé permettant de coordonner les processus dans un environnement distribué. ZooKeeper est essentiel au bon fonctionnement de Kafka, c’est pour cela qu’il est empaqueté dans Kafka.
Définition plus fine
Kafka a un vocabulaire bien spécifique, cette partie a pour objectif de vous présenter ce vocabulaire. Je ne vais pas rentrer dans le détail (loin de là). Le but est simplement de donner le vocabulaire et la connaissance nécessaire pour faire tourner Kafka sur votre machine.
Comme dit plus haut, Kafka fait le lien entre producteurs et consommateurs et gère les accès de chacun. Pour faciliter la compréhension, il ne faut pas voir un unique flux entre les producteurs et les consommateurs mais plusieurs flux. Ces flux sont appelés des topics. Ainsi, on va pouvoir inscrire des producteurs et des consommateurs à ces topics : « Le producteur A publie dans le topic #1 », « Le consommateur B consomme les données des topics #1 et #2 », etc. Chaque topic est partitionné. Cela permet la résistance à la pane de machines entre autres.
Ci-après le graphique que tout le monde utilise pour représenter l’anatomie d’un topic Kafka :
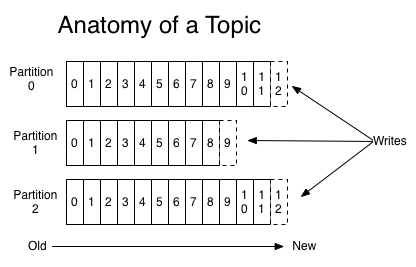
Voilà l’essentiel à savoir sur le fonctionnement et le vocabulaire de Kafka. Evidemment, l’affaire est bien plus complexe. Pour en savoir d’avantage (notamment sur les répliquas de partition pour des raisons de sécurité et de non perte de données), rendez-vous sur le site officiel.
Mise en pratique
Objectif du programme
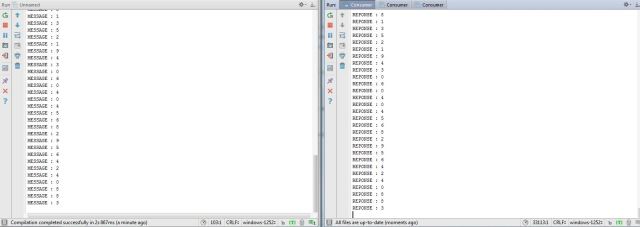
Le programme présenté est très simpliste tout en étant complet. Il va être question de coder un producteur et un consommateur. Le producteur va envoyer un chiffre aléatoire entre 0 et 9 toutes les demies secondes. Le consommateur va récupérer ce chiffre et l’afficher dans sa console.
Pour faire fonctionner ce programme, il est nécessaire de télécharger Kafka. Comme dit dans l’introduction, la version utilisée dans l’exemple est 0.8.2.0. Vous pourrez la trouver sur le site officiel, ici. Téléchargez la version de votre choix et dé-zippez la où ça vous arrange (dans /lib de votre projet Intellij par exemple).
Architecture
Pour réaliser ce programme est il nécessaire de comprendre l’architecture d’un projet Kafka. Pour faire fonctionner un programme Kafka il vous faut 4 choses distinctes :
Démarrer le serveur ZooKeeper
Pour démarrer votre ZooKeeper, ouvrez une console windows et naviguez jusqu’à la racine de votre Kafka. Ici, vous lancez le fichier zookeeper-server-start.bat en précisant le fichier properties de zookeeper en argument qui se trouve dans le dossier config/ (config/zookeeper.properties). Personnellement, je n’ai pas modifié ce fichier, mais si des contraintes s’imposent à vous, c’est ici qu’on configure zookeeper (port, hôte et compagnie).
Si vous êtes à la racine de Kafka, la commande est la suivante :
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
Et vous devriez obtenir :
Démarrer le serveur Kafka
De la même manière que pour Zookeeper, il est nécessaire de lancer le serveur Kafka. Ouvrez une autre console, positionnez vous à la racine de Kafka et tapez dans votre console :
bin\windows\kafka-server-start.bat config\server.properties
Vous devriez obtenir :
Programmer le(les) producteur(s) ET le(les) consommateur(s)
Vous devez être capable de lancer votre producteur indépendamment de votre consommateur. Ainsi, créez deux programmes distincts. Pour ma part, j’ai créé deux projets Intellij différents. Cela me permet de lancer mes programmes depuis Intellij. Intellij vous proposant de gérer un projet par fenêtre, c’est parfait.
Pensez à bien importer les dépendances Kafka sur les deux projets pour pouvoir coder vos producteurs/consommateurs avec l’API. Plus loin, je donne le contenu des fichiers build.sbt qui gèrent les dépendances de mes projets.
Le programme
Les dépendances
Une fois que la théorie est à peu près intégrée, il est temps de passer à la pratique. D’ailleurs, je conseille de ne pas trop s’attarder sur la théorie. Il n’y a pas de priorité sur la mise en place du producteur ou du consommateur. L’un peut fonctionner sans l’autre et vis et versa.
Avant de commencer le code, pensez à créer les dépendances avec Kafka pour avoir accès à l’API. Utilisez la méthode de votre choix : SBT ou import à la main. Pour ma part, j’ai pris l’habitude de travailler avec SBT, je vous copie colle le contenu de mes fichiers build.sbt de mes deux projets :
build.sbt du producteur :
name := "TEST-PRODUCER"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies += "org.apache.kafka" % "kafka_2.11" % "0.8.2.0"
build.sbt du consommateur :
name := "TEST-CONSUMER"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies += "org.apache.kafka" % "kafka_2.11" % "0.8.2.0"
Producteur
Les properties
La première chose à faire, avant de toucher à l’API est de crée la configuration de votre producteur via la classe Properties (une classe java.util). Voilà mon morceau de code, je l’explique ensuite :
// DEFINITION DES PROPERTIES
val props = new Properties()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, localhost:9092)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
J’indique que je vais faire tourner Kafka sur ma machine (localhost) et que je vais utiliser le port 9092 pour la communication. Ce port est le port généralement utilisé par Kafka. Vous le retrouverez dans le fichierconfig/server.properties de votre dossier Kafka.
J’indique aussi que mes messages (clé + valeur) qui vont transiter seront du type String. Pour cela, Kafka a un serializer tout prêt que je vous conseille d’utiliser.
Il existe de nombreuses configurations possibles. J’ai mis le minimum vital pour que ça marche dans l’exemple. Pour connaitre toutes les variables possibles, deux choix : Accédez à la classe ProducerConfig.java, elle est bien commentée ou visitez la documentation sur le site officiel, à cette page. A noter qu’il existe les « anciennes » configurations et les « nouvelles ». Les nouvelles sont plus claires car elles sont sous forme de variables globales et ainsi retrouvables facilement via l’auto-complétion.
L’objet producer
Ici, il est question de créer l’objet producer. C’est avec ce dernier que vous allez envoyer vos messages. Pour l’instancier, le producer a besoins des configurations qu’on vient de mettre en place et des types de la clé et de la valeur des messages que vous souhaitez envoyer. Comme vu dans lesproperties, la clé et la valeur seront de type String. On obtient donc :
val producer = new KafkaProducer[String, String](props)
La production et l’envoi des données
Ici, deux choses sont importantes :
- La création d’un message via la classe ProductRecord
- L’envoi de vos messages dans le bon topic via la méthode send() appliquée à l’objet producer.
Pour rappel, je souhaite envoyer un chiffre entre 0 et 9 toutes les demies secondes. Je vous copie colle le code :
// ON ENVOIE TOUT
while (true) {
val str = scala.util.Random.nextInt(10).toString
val message = new ProducerRecord[String, String]("monTopic", null, str)
producer.send(message)
println("MESSAGE : " + str)
Thread.sleep(500)
}
On retrouve donc la ligne me permettant de générer un chiffre aléatoirement. On note que je le caste en String pour respecter ce que j’ai énoncé plus tôt.
La création de mon message se fait donc via la création d’un objetProducerRecord auquel j’associe les bons types pour la clé et la valeur de mon message. En argument je lui donne le topic auquel je souhaite contribuer (une chaîne de caractères suffit) ainsi que mon message.
Ensuite, j’envoie ce message via la méthode send() qui n’a pas d’argument particulier mis à part le message.
Enfin, je débug en affichant ce que j’envoie et j’attends un demie seconde avant l’envoi du prochain message.
Consommateur
Les properties
Tout comme pour le producteur, le consommateur a aussi besoins d’un minimum de properties. Cependant, il n’existe pas de variables globales comme pour le producteur (rappelez vous des « nouvelles » configurations). Voilà à quoi ressemble ma variable de configuration :
val props = new Properties()
props.put("group.idonPremierGroupID")
props.put("zookeeper.connectocalhost:2181")
props.put("auto.offset.resetmallest")
Je n’ai pas parlé du Group ID dans cet article car ça ne fait que compliquer les choses. Ce qu’il faut savoir c’est qu’on regroupe les consommateurs dans des groupes qui suivent les mêmes topics. Plus d’explications sur le site officiel. Quoiqu’il en soit, pour une phase de test, le group.id importe très peu puisque vous exécutez le code sur votre propre machine et non pas un maxi cluster.
La seconde propriété indique l’hôte et le port de ZooKeeper. Nous sommes en local dont l’hôte est localhost et le port de ZooKeeper est par convention 2181. Vous retrouverez ces informations dans le fichier config/zookeeper.properties.
Enfin, dans la dernière propriété, j’indique que je souhaite traiter les messages par ordre croissant de leur offset (numéro attribué lors de l’envoi d’un message dans le flux). Ainsi les messages de mon topic sont lus à la manière d’une fileFIFO (First In First Out).
La liste de toutes les propriétés configurables des consommateurs sont dispoici.
Création du consommateur
Pour créer le consommateur, il faut d’abord créer un objet ConsumerConfig. Rien est très compliqué ici, voilà les deux lignes nécessaires :
val config = new ConsumerConfig(props)
val connector = Consumer.create(config)
Définition des topics à suivre
Il faut ensuite définir la liste des topics à suivre (il faut voir ça comme un filtre) et donc à ajouter à notre WhiteList. Rien de compliqué non plus, voilà le code :
val filterSpec = new Whitelist(topic)
Création du stream
La partie la plus intéressante du consommateur, la création du stream. Ici, il est question de créer le stream et de réagir à chaque nouveau message.
val stream = connector.createMessageStreamsByFilter(filterSpec, 1, new StringDecoder(null), new StringDecoder(null))(0)
val it = stream.iterator()
while(it.hasNext()) {
println("REPONSE : " + it.next().message())
}
Pour créer le stream, on utilise la méthode createMessageStreamsByFilterappliquée à notre consommateur. Le filtre étant notre WhiteList, nous la fournissons en argument. Nous fournissons également les décodeurs pour la clé et le contenu du message. Et oui, pour rappel, avant de les insérer dans le flux, nous les avions sérialisés. Pour décoder en String, nous utilisons l’objetStringDecoder. A la fin de la première ligne, on indique que l’on souhaite accéder au premier élément du stream avec (0).
Ensuite, via un iterator, on va boucler sur nos messages et simplement en afficher le contenu.
Exécuter le programme
Pour exécuter le programme, pensez à lancer le serveur ZooKeeper en premier puis le serveur Kafka. Ensuite lancez indépendamment le programme du consommateur et du producteur (l’ordre du lancement n’importe en rien).
De mon coté, voilà un extrait des sorties avec à gauche le producteur et à droite le consommateur.